
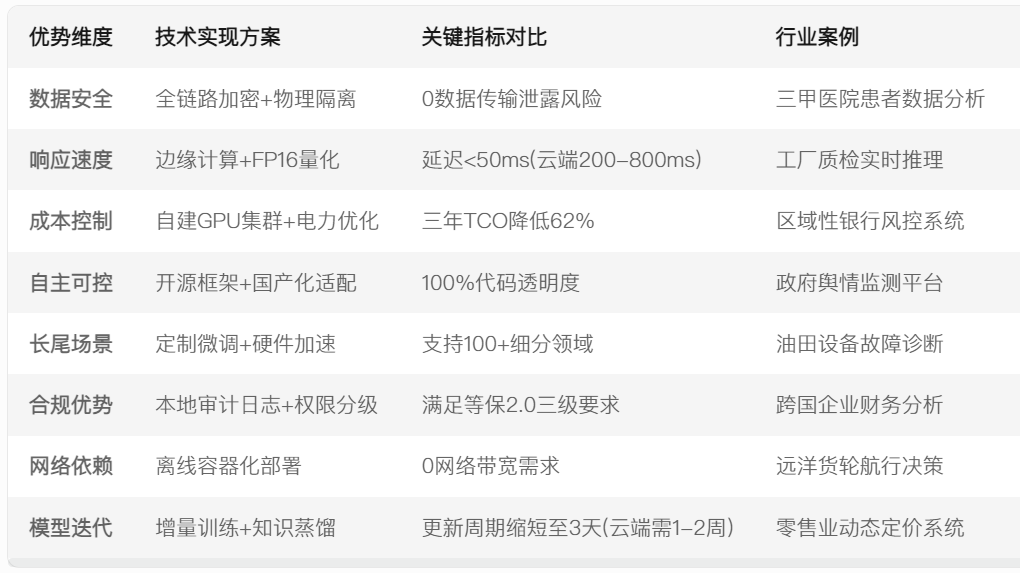
DeepSeek是一款基于AI技术的智能搜索引擎,结合深度学习与自然语言处理,提供精准、高效的搜索体验。探索DeepSeek,感受未来智能搜索的无限可能!Deepseek作为国产大模型代表,其本地部署需求折射出AI应用对硬件生态的深刻影响。在Deepseek本地化部署的硬件拼图中,内存模块正经历从后勤配角到算力推手的角色转换,本地化部署正在掀起新一轮硬件革命。

在ChatGPT引爆全球AI热潮后,大模型部署正经历从云端到终端的范式转移。OpenAI的GPT-4o模型已实现端侧部署,Meta的Llama 3系列更将模型参数压缩至7B级别。这种技术演进使得本地部署不再是极客专属,普通用户也能在个人设备上运行智能助手。
数据安全需求驱动着这一变革。医疗、金融等行业对隐私保护的严苛要求,迫使AI应用必须实现本地闭环。微软Azure AI最新报告显示,2024年企业级AI部署中,混合云架构占比已达67%,其中本地算力承担核心数据处理任务。
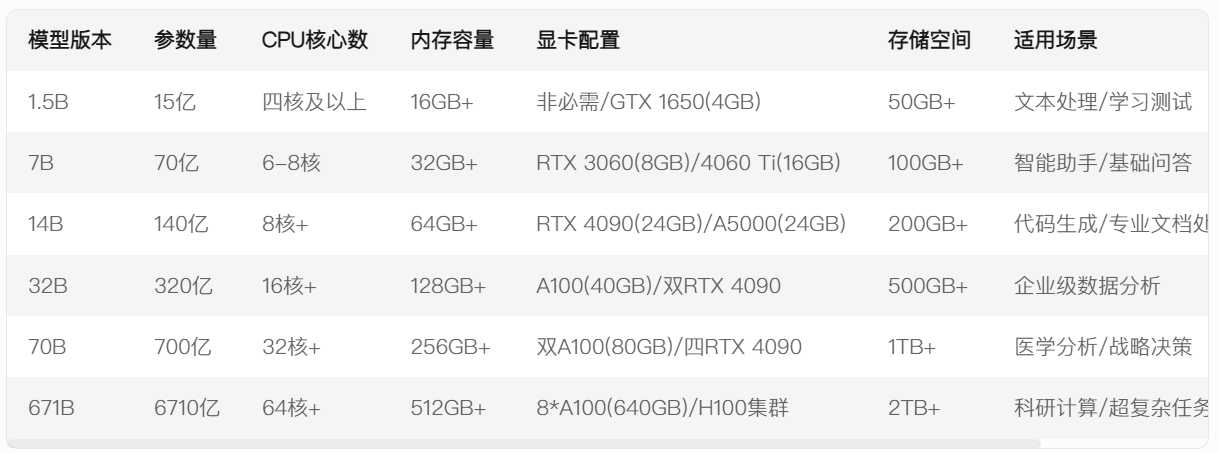
在Deepseek本地部署实践中,内存选择需遵循模型参数×1.5的配置原则。以主流的14B模型为例,其参数规模约140亿,实际运行需21GB显存空间。此时双通道DDR5 16GB×2内存组合,配合智能缓存技术,可确保模型推理时带宽吞吐量稳定在80GB/s以上。
光威龙武DDR5 6400MHz内存的实测表现印证了这一理论。在Llama-2-13B推理测试中,对比传统DDR4 3200MHz方案,其token生成速度提升37%,功耗降低22%。这种性能跃升源于DDR5架构的Bank Group设计,将有效带宽利用率提升至92%。

内存技术正与AI芯片深度耦合。英伟达H100 GPU的HBM3e显存带宽已达3.35TB/s,而AMD锐龙8000系列APU的混合内存架构,允许CPU直接访问显存池。这种硬件协同使70B级大模型在消费级平台运行成为可能。
国产硬件生态的突破尤为值得关注。长鑫存储的LPDDR5X芯片良率突破85%,光威神武系列内存采用的3D堆叠封装技术,将单条容量提升至48GB。这些创新使中国企业在AI硬件赛道实现弯道超车。

站在AI普惠化转折点,硬件选择已不仅是性能参数的堆砌。用户需在模型效能、硬件成本、能耗控制间寻找动态平衡。随着QLC闪存、CXL互联等新技术成熟,未来本地AI部署将呈现模型轻量化、硬件专用化趋势。在这场静悄悄的硬件革命中,选择合适的内存配置,本质上是在为智能未来购买时间期权。