
DeepSeek是一款基于AI技术的智能搜索引擎,结合深度学习与自然语言处理,提供精准、高效的搜索体验。探索DeepSeek,感受未来智能搜索的无限可能!DeepSeek R2的研究成果已经接近。最近,DeepSeek和清华大学的研究者发表了一篇论文,探讨了奖励模型在推理时的Scaling方法。

强化学习(RL)已广泛应用于大规模语言模型(LLM)的后训练阶段。通过RL激励LLM的推理能力表明,采用合适的学习方法可以实现有效的推理时可扩展性。然而,RL面临的一个关键挑战是在多种领域中为LLM获得准确的奖励信号。
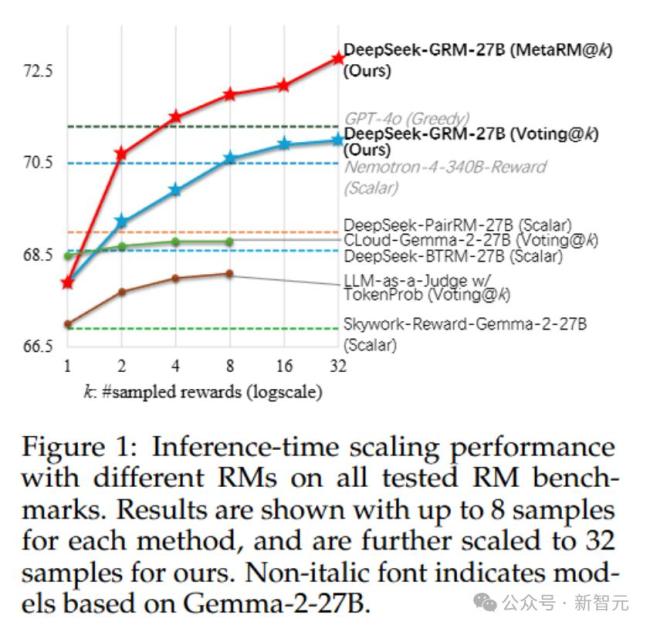
研究者发现,在奖励建模(RM)方法上采用点式生成式奖励建模(GRM),可以提升模型对不同输入类型的灵活适应能力,并具备推理阶段可扩展的潜力。为此,他们提出了一种自我原则点评调优(SPCT)的学习方法。这种方法通过在线RL训练促进GRM生成具备可扩展奖励能力的行为,即能够自适应生成评判原则并准确生成点评内容,从而得到DeepSeek-GRM模型。
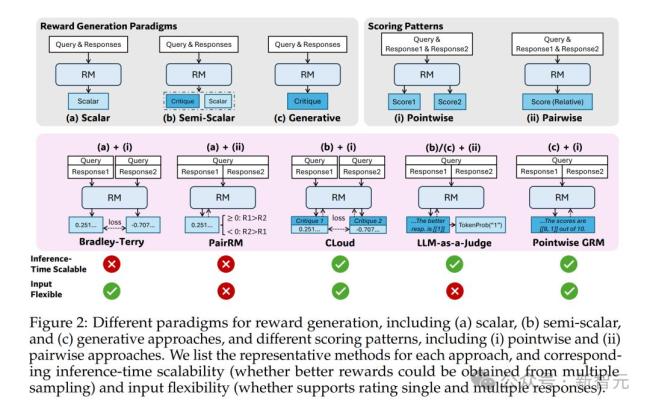
DeepSeek-GRM-27B是基于Gemma-2-27B经过SPCT后训练的。实验结果表明,SPCT显著提高了GRM的质量和可扩展性,在多个综合RM基准测试中优于现有方法和模型。研究者还比较了DeepSeek-GRM-27B与671B更大模型的推理时间扩展性能,发现它在模型大小上的训练时间扩展性能更好。此外,他们引入了一个元奖励模型(meta RM)来引导投票过程,以提升扩展性能。
伯克希尔辟谣:社交媒体上关于巴菲特讲话的消息都是虚假的 假言论误导公众
2月18日,DeepSeek官方在海外社交平台X上发布了一篇关于NSA(Natively Sparse Attention,原生稀疏注意力)的技术论文。这种机制用于超快速长文本训练与推理,硬件对齐且可原生训练
黄仁勋揭秘下一代芯片Rubin,英伟达想要吃“DeepSeek红利” 推理时代的新机遇
科技界的重要人物黄仁勋刚刚完成了他年度最重要的演讲。黄仁勋称他的GTC演讲就像AI界的超级碗,吸引了全球各地数万人聚集在美国圣何塞参加这场盛会。演讲于2025年3月18日举行,市区因参会人数过多而拥堵瘫痪,不少人早上6点就开始排队等待